Adapter Activation and Composition
With adapters, it becomes possible to combine multiple adapters trained on different tasks in so-called adapter compositions.
To enable such compositions, adapters comes with a modular and flexible concept to define how the input to the model should flow through the available adapters.
This allows, e.g., stacking (MAD-X) and fusing (AdapterFusion) adapters and even more complex adapter setups.
Adapter Activation
The single location where all the adapter composition magic happens is the active_adapters property of the model class.
In the simplest case, you can set the name of a single adapter here to activate it:
model.active_adapters = "adapter_name"
Important
active_adapters defines which available adapters are used in each forward and backward pass through the model. This means:
You cannot activate an adapter before previously adding it to the model using either
add_adapter()orload_adapter().All adapters not mentioned in the
active_adapterssetup are ignored, although they might have been loaded into the model. Thus, after adding an adapter, make sure to activate it.
Note that we also could have used the set_active_adapters method with model.set_active_adapters("adapter_name") which does the same.
Alternatively, the AdapterSetup context manager allows dynamic configuration of activated setups without changing the model state:
from adapters import AdapterSetup
model = ...
model.add_adapter("adapter_name")
with AdapterSetup("adapter_name"):
# will use the adapter named "adapter_name" in the forward pass
outputs = model(**inputs)
Composition Blocks - Overview
The basic building blocks of the more advanced setups are objects derived from AdapterCompositionBlock,
each representing a different possibility to combine single adapters.
The following table gives an overview on the supported composition blocks and their support by different adapter methods.
| Block | Bottleneck Adapters |
Prefix Tuning |
Compacter | LoRA | (IA)³ | Vera | Dora | Prompt Tuning |
|---|---|---|---|---|---|---|---|---|
Stack |
✅ | ✅ | ✅ | ✅(*) | ✅(*) | ✅(*) | ✅(*) | |
Fuse |
✅ | ✅ | ||||||
Split |
✅ | ✅ | ||||||
BatchSplit |
✅ | ✅ | ✅ | ✅(*) | ✅(*) | ✅(*) | ✅(*) | |
MultiTask |
✅ | ✅ | ✅ | ✅(*) | ✅(*) | ✅(*) | ✅(*) | |
Parallel |
✅ | ✅ | ✅ | ✅(*) | ✅(*) | ✅(*) | ✅(*) | |
| Output averaging | ✅ | ✅ | ✅(*) | ✅(*) | ✅(*) | ✅(*) | ||
| Parameter averaging | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
(*) except for Deberta, GPT-2 and ModernBERT.
Next, we present all composition blocks in more detail.
Stack
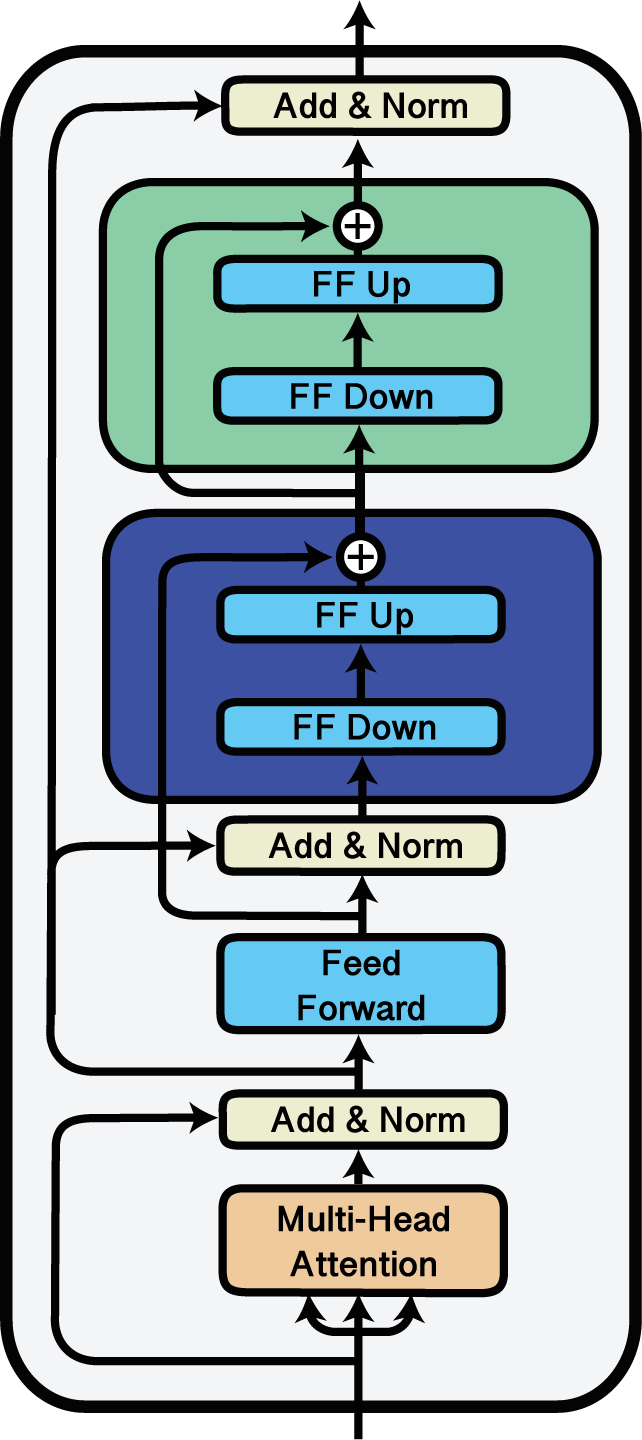
Stacking adapters using the ‘Stack’ block.
The Stack block can be used to stack multiple adapters on top of each other.
This kind of adapter composition is used e.g. in the MAD-X framework for cross-lingual transfer (Pfeiffer et al., 2020), where language and task adapters are stacked on top of each other.
For more, check out this Colab notebook on cross-lingual transfer.
In the following example, we stack the adapters a, b and c so that in each layer, the input is first passed through a, the output of a is then inputted to b and the output of b is finally inputted to c.
import adapters.composition as ac
// ...
model.add_adapter("a")
model.add_adapter("b")
model.add_adapter("c")
model.active_adapters = ac.Stack("a", "b", "c")
Note
When using stacking for prefix tuning the stacked prefixed are prepended to the input states from right to left, i.e. Stack(“a”, “b”, “c”) will first prepend prefix states for “a” to the input vectors, then prepend “b” to the resulting vectors etc.
Fuse
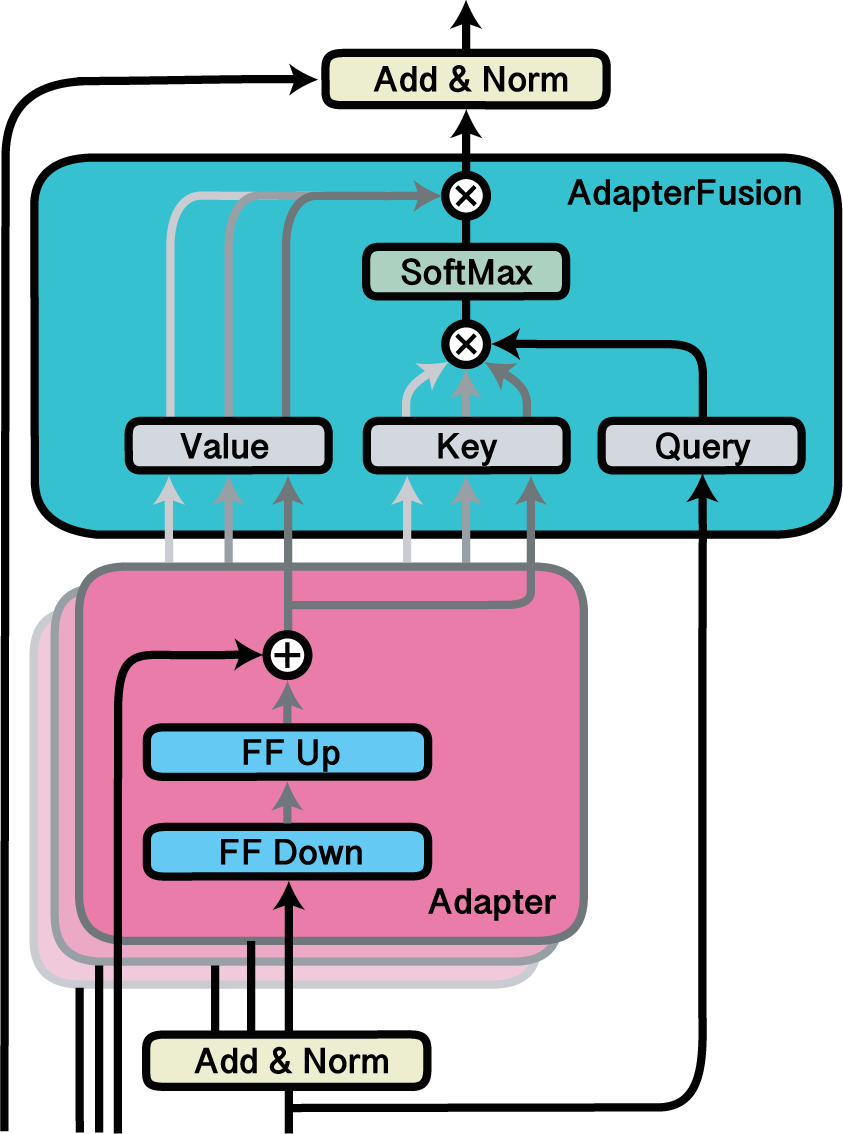
Fusing adapters with AdapterFusion.
The Fuse block can be used to activate a fusion layer of adapters.
AdapterFusion is a non-destructive way to combine the knowledge of multiple pre-trained adapters on a new downstream task, proposed by Pfeiffer et al., 2021.
In the following example, we activate the adapters d, e and f as well as the fusion layer that combines the outputs of all three.
The fusion layer is added beforehand using model.add_adapter_fusion(), where we specify the names of the adapters which should be fused.
import adapters.composition as ac
// ...
model.add_adapter("d")
model.add_adapter("e")
model.add_adapter("f")
model.add_adapter_fusion(["d", "e", "f"])
model.active_adapters = ac.Fuse("d", "e", "f")
Important
Fusing adapters with the Fuse block only works successfully if an adapter fusion layer combining all of the adapters listed in the Fuse has been added to the model.
This can be done either using add_adapter_fusion() or load_adapter_fusion().
To learn how training an AdapterFusion layer works, check out this Colab notebook from the adapters repo.
To save and upload the full composition setup with adapters and fusion layer in one line of code, check out the docs on saving and loading adapter compositions.
Retrieving AdapterFusion attentions
Finally, it is possible to retrieve the attention scores computed by each fusion layer in a forward pass of the model.
These scores can be used for analyzing the fused adapter blocks and can serve as the basis for visualizations similar to those in the AdapterFusion paper.
You can collect the fusion attention scores by passing output_adapter_fusion_attentions=True to the model forward call.
The scores for each layer will then be saved in the adapter_fusion_attentions attribute of the output:
outputs = model(**inputs, output_adapter_fusion_attentions=True)
attention_scores = outputs.adapter_fusion_attentions
Note that this parameter is only available to base model classes and AdapterModel classes.
In the example, attention_scores holds a dictionary of the following form:
{
'<fusion_name>': {
<layer_id>: {
'<module_location>': np.array([...]),
...
},
...
},
...
}
Split
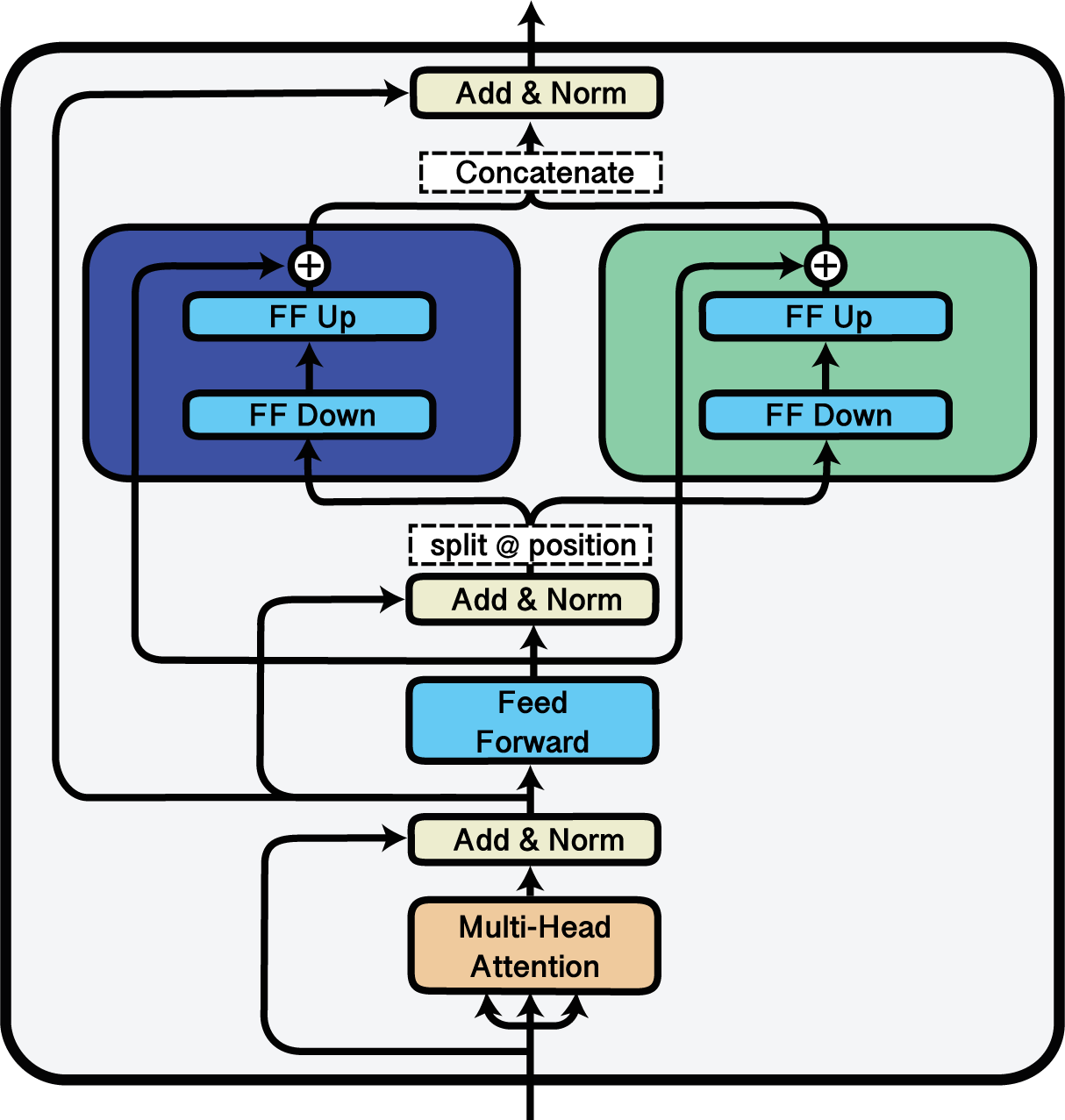
Splitting the input between two adapters using the ‘Split’ block.
The Split block can be used to split an input sequence between multiple adapters.
This is done by specifying split indices at which the sequences should be divided.
In the following example, we split each input sequence between adapters g and h.
For each sequence, all tokens from 0 up to 63 are forwarded through g while the next 64 tokens are forwarded through h:
import adapters.composition as ac
// ...
model.add_adapter("g")
model.add_adapter("h")
model.active_adapters = ac.Split("g", "h", splits=[64, 64])
BatchSplit
The BatchSplit block is an alternative to split the input between several adapters. It does not split the input sequences but the
batch into smaller batches. As a result, the input sequences remain untouched.
In the following example, we split the batch between adapters i, k and l. The batch_sizesparameter specifies
the batch size for each of the adapters. The adapter i gets two sequences, kgets 1 sequence and l gets two sequences.
If all adapters should get the same batch size this can be specified by passing one batch size e.g. batch_sizes = 2. The sum
specified batch has to match the batch size of the input.
import adapters.composition as ac
// ...
model.add_adapter("i")
model.add_adapter("k")
model.add_adapter("l")
model.active_adapters = ac.BatchSplit("i", "k", "l", batch_sizes=[2, 1, 2])
MultiTask
The MultiTask block extends BatchSplit by enabling dynamic batch splitting based on task_ids provided to the forward method.
In the example below, the batch is dynamically divided among adapters i, k, and l based on task_ids assigned to each sequence. This approach supports flexible multi-task learning without requiring fixed batch sizes per adapter.
Important
MultiTask can only be used with config that inherits from MultiTaskConfig.
When training multi-task adapters, task_ids mus be an integer tensor indicating the adapter positions.
For inference, task_ids can be a list of task names.
from adapters import MTLLoRAConfig
import adapters.composition as ac
// ...
# config must inherit from MultiTaskConfig
config = MTLLoRAConfig()
model.add_adapter("i", config)
model.add_adapter("k", config)
model.add_adapter("l", config)
model.share_parameters(
adapter_names=["i", "k", "l"],
)
model.active_adapters = ac.MultiTask("i", "k", "l")
# input batch size = 3
model.forward(**inputs, task_ids=torch.tensor([2, 1, 0])) # 2 → "l", 1 → "k", 0 → "i"
# Equivalent inference call
model.forward(**inputs, task_ids=["l", "k", "i"])
Parallel
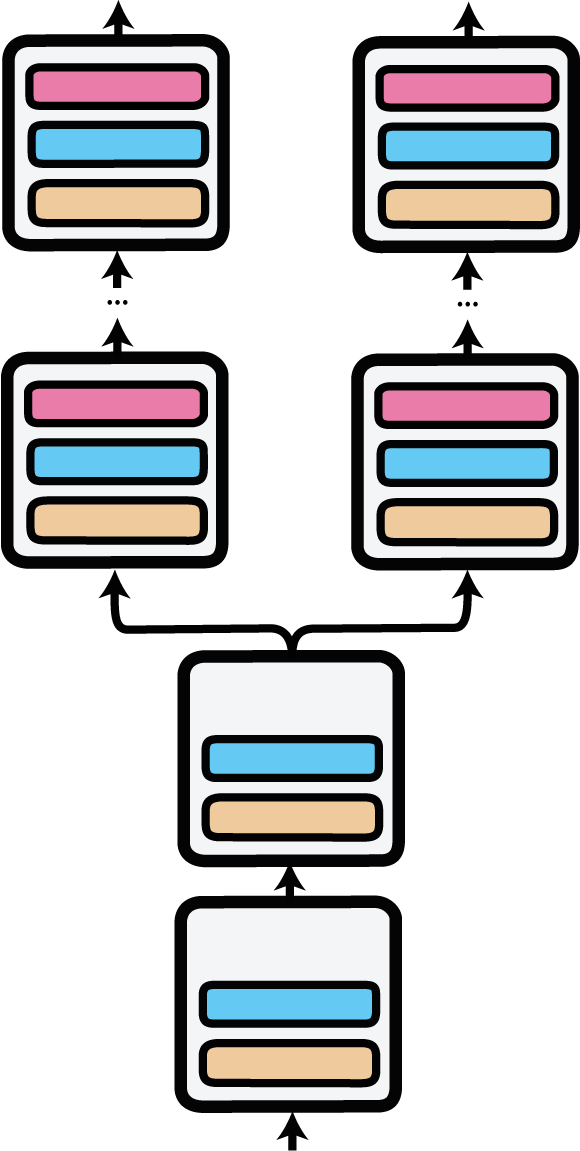
Parallel adapter forward pass as implemented by the ‘Parallel’ block. The input is replicated at the first layer with parallel adapters.
The Parallel block can be used to enable parallel multi-task training and inference on different adapters, each with their own prediction head.
Parallel adapter inference was first used in AdapterDrop: On the Efficiency of Adapters in Transformers (Rücklé et al., 2020).
In the following example, we load two adapters for semantic textual similarity (STS) from the Hub, one trained on the STS benchmark, the other trained on the MRPC dataset. We activate a parallel setup where the input is passed through both adapters and their respective prediction heads.
import adapters.composition as ac
model = AutoAdapterModel.from_pretrained("distilbert-base-uncased")
tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
adapter1 = model.load_adapter("sts/sts-b@ukp")
adapter2 = model.load_adapter("sts/mrpc@ukp")
model.active_adapters = ac.Parallel(adapter1, adapter2)
input_ids = tokenizer("Adapters are great!", "Adapters are awesome!", return_tensors="pt")
output1, output2 = model(**input_ids)
print("STS-B adapter output:", output1[0].item())
print("MRPC adapter output:", bool(torch.argmax(output2[0]).item()))
Output averaging
Recent work on adapters has explored methods to ensemble models for better generalization. This includes averaging output representations of adapters (Wang et al., 2021) as well as averaging adapter parameters (Wang et al., 2022, Chronopoulou et al., 2023). Adapters provides built-in support for both types of inference-time averaging methods. The output averaging composition block is described below and merging adapter parameters is explained in the Merging Adapters documentation page.
Output averaging allows the dynamic aggregation of output representations of multiple adapters in a model forward pass via weighted averaging. This is realized via the Average composition block, which works similarly to other composition blocks.
In the example below, the three adapters are averaged with the weights 0.1 for m, 0.6 for n and 0.3 for o.
import adapters.composition as ac
// ...
model.add_adapter("m")
model.add_adapter("n")
model.add_adapter("o")
model.active_adapters = ac.Average("m", "n", "o", weights=[0.1, 0.6, 0.3])
Nesting composition blocks
Of course, it is also possible to combine different composition blocks in one adapter setup.
E.g., we can nest a Split block within a Stack of adapters:
import adapters.composition as ac
model.active_adapters = ac.Stack("a", ac.Split("b", "c", splits=60))
However, combinations of adapter composition blocks cannot be arbitrarily deep. All currently supported possibilities are visualized in the table below.
| Block | Supported Nesting |
|---|---|
Stack |
[str, Fuse, Split, Parallel, BatchSplit, Average] |
Fuse |
[str, Stack] |
Split |
[str, Split, Stack, BatchSplit, Average] |
Parallel |
[str, Stack, BatchSplit, Average] |
BatchSplit |
[str, Stack, Split, BatchSplit, Average] |
MultiTask |
[str, Stack, Split, BatchSplit, Average] |
Average |
[str, Stack, Split, BatchSplit] |
In the table, str represents an adapter, e.g. adapter “a” in the nesting example above. Depending on the individual model, some nested compositions might not be possible.